Kafka一二事
背景
公司最近新上一个项目,我负责获取上游数据,经过过滤、处理后,分发给下游各个场景。我司大多数部门重度依赖kafka,此项目中与kafka打交道的地方也甚多。
为了代码质量,也为了之后能快速定位与kafka相关的问题,所以略微研究了kafka相关知识,写作此文,以备后记。
相关技术栈: Java Kafka springBoot
topic与partition
kafka集群有多台broker组成,集群中每台broker没有主从之分。kafka集群属于对称架构,集群启动时会进行选举,选举一个controller出来,其选举过程依赖zk集群。这个controller负责管理整个集群的partition和partition副本状态、保证集群meta信息的一致性等工作。
例如某topic某partition leader挂了,该controller负责选出新的partition leader;
例如集群新增broker、新创建topic,或者为某topic扩缩容,都需要controller作相关处理。
一个topic可以有多个partition,每个partition可以设置自己的复制因子,这样设计的目的一来可以提高消费者消费的吞吐量,二来冗余数据防止不会因为某台broker的挂掉导致数据的丢失。
假设broker集群有5台机器,某topic设置3个partition,复制因子设为2,则broker集群中有3台机器作为该topic的partition机器,每台partition机器再次选其余4台机器的随机一台机器作为partition副本。 假设某台机器挂掉,controller找到丢失心跳的机器,然后将其副本升为partition leader,然后随机选另外一台机器作为partition副本,保证服务可用性和数据一致性。
如何保证同一条数据先后到达时,保证被consumer顺序消费?
我们知道,每一个consumer消费的是topic中partition中的数据,每个consumer消费的partition不同,消费能力自然也不同,所以要保证同一条数据的顺序消费,须要保证同一条数据入同一个partition,这样就可以保证数据的顺序消费。

我司场景中,每一条数据都有自己的唯一标识,所以在构建ProducerRecord时,以此唯一标识作为key,用来保证同一条数据的顺序消费。
offset记录与提交
offset分为两种,一种保存在服务器端,一种保存在消费者客户端,保存在服务器端的offset称为committed offset,保存在消费者客户端的offset称为current offset。
current offset保留在消费者客户端,含义是下一次poll时要去拉取的offset;committed offset保留在服务端,含义是当发生rebalance时,服务器给消费者端推message的起始位置。
怎么根据offset确定message的所在位置?
offset的保存是按照groupid-topic-partition存放的,当consumer去poll时,自身已知groupid、topic、partition和要拉取的offset,根据这4个参数可以知道message所在的位置,然后去拉取数据即可。
kafka broker rebalance
什么是rebalance? 从表现上来看,kafka根据保留在服务端的offset,重新分配给订阅该topic的group中的consumer。
kafka broker rebalance的动作发在kafka服务端,导致rebalance的原因有很多,常见的有以下几种:
1,consumer group中consumer数量或状态发生变化
2,consumer消费太慢提交offset太晚,导致出现rebalance
Error while processing: org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
之前有同事碰到过相似的问题,看监控显示kafka消费能力明显下降,每分钟只能消费几十条,导致lag不断增加。后来查找原因是业务逻辑中调用的某个http接口超时重试时间太长,导致提交offset超时,一直处于rebalance状态,consumer其实一直在重复着消费最新的消息,导致消费能力明显下降。
在项目中,跟rebalance相关的配置有以下几个:

heartbeat.interval.ms:consumer向group coordinator发送heartbeat的间隔时间
session.timeout.ms:coordinator认为consumer挂掉的时间
max.poll.interval.ms:两次poll之间的最大间隔时长
max.poll.records:每次poll的最大数量

新版本的kafka中,分离出heartbeat线程和消费线程,如上图,heartbeat线程每隔heartbeat.interval.ms时间发送一个heartbeat给group coordinator,如果在session.timeout.ms时间内仍然没有 收到heartbeat,则group coordinator认为group中某consumer挂掉,则集群会发生rebalance;消费线程受max.poll.interval.ms和max.poll.records控制,假设一次poll了max.poll.records条 record,但却在max.poll.interval.ms内受其它因素影响没有提交offset,group coordinator会认为消费线程没有正确处理处理,集群会发生rebalance,根据服务端的offset记录重新分配给consumer group中 的consumer进行消费。
多线程消费与异常处理
topic可以有多个partition,上面提到多分区可以提高消费者的吞吐量是什么意思呢?
一个consumer group中可以有多个consumer,这些consumer有共同的group-id,当一个consumer group订阅某个topic消费的时候,其实是该group下的consumer与topic下的partition的对应关系。 假设topic有12个分区,一个consumer group中有12个consumer,则将是一个consumer和一个partition的一一对应关系;
若consumer group中有10个consumer,则将有8个consumer各单独消费一个partition,2个consumer消费2个partition;
若consumergroup中有15个consumer,则将有3个consumer空闲,不会分配partition使其消费。
当一个consumer group中有多个consumer消费同一个topic时,也就提高了吞吐量。springboot中有专门的配置这一属性:

当我们消费topic时,取出的数据是二进制流,需要反序列化成对象才能处理。由于kafka本身没有类似schema校验的东西,所以需要在producer和consumer 在生产和消费额时候保持约定,但难免会有一些不规范的数据格式;另外,在消费过程中,可能会抛出一些没有捕获的异常,所以为了程序的健壮性,异常处理是十分必要的。
异常处理有两种方式:
一是在代码内try…catch…进行处理,这种实现方式简单粗暴,但将异常处理逻辑与业务逻辑混在一起,不太直观优雅
二是在进行kafkaListenerContainerFactory构建过程中,实现ConsumerAwareListenerErrorHandler类中handleError方法,将异常处理逻辑放在此处,解耦了业务逻辑与异常逻辑。
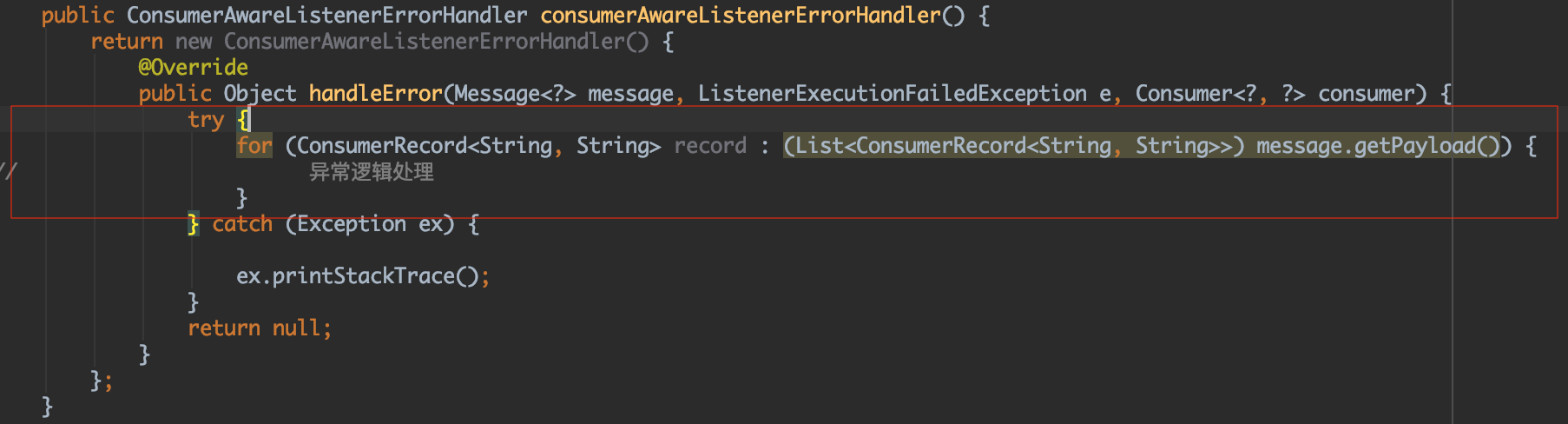
同时测试发现,在kafkaListener中抛出异常时,此异常会被这个方法捕获,不会再向上抛出,所以不会导致线程销毁再创建,适合我们的业务场景。
kafka VS rocketmq https://www.cnblogs.com/jager/p/6385610.html 数据可靠性 RocketMQ支持异步实时刷盘,同步刷盘,同步复制,异步复制 卡夫卡使用异步刷盘方式,异步复制/同步复制
性能对比 卡夫卡单机写入TPS约在百万条/秒,消息大小10个字节 RocketMQ单机写入TPS单实例约7万条/秒,单机部署3个Broker,可以跑到最高12万条/秒,消息大小10个字节
单机支持的队列数 Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长。Kafka分区数无法过多的问题 RocketMQ单机支持最高5万个队列,负载不会发生明显变化
消息投递实时性 Kafka使用短轮询方式,实时性取决于轮询间隔时间,0.8以后版本支持长轮询。 RocketMQ使用长轮询,同Push方式实时性一致,消息的投递延时通常在几个毫秒。
消费失败重试 卡夫卡消费失败不支持重试。 RocketMQ消费失败支持定时重试,每次重试间隔时间顺延
严格的消息顺序 卡夫卡支持消息顺序,但是一台代理宕机后,就会产生消息乱序 RocketMQ支持严格的消息顺序,在顺序消息场景下,一台Broker宕机后,发送消息会失败,但是不会乱序。
定时消息 卡夫卡不支持定时消息 RocketMQ支持两类定时消息 开源版本RocketMQ仅支持定时级别,定时级用户可定制
消息查询 卡夫卡不支持消息查询 RocketMQ支持根据消息标识查询消息,也支持根据消息内容查询消息(发送消息时指定一个消息密钥,任意字符串,例如指定为订单编号)
消息回溯 卡夫卡可以根据消费者group按照偏移来回溯消息 RocketMQ支持按照时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息
消费并行度 Kafka的消费并行度依赖Topic配置的分区数,如分区数为10,那么最多10台机器来并行消费(每台机器只能开启一个线程),或者一台机器消费(10个线程并行消费)。即消费并行度和分区数一致。 RocketMQ消费并行度分两种情况 顺序消费方式并行度同卡夫卡完全一致 乱序方式并行度取决于Consumer的线程数,如Topic配置10个队列,10台机器消费,每台机器100个线程,那么并行度为1000。
消息堆积能力 理论上Kafka要比RocketMQ的堆积能力更强,不过RocketMQ单机也可以支持亿级的消息堆积能力,我们认为这个堆积能力已经完全可以满足业务需求。
解耦是消息队列所要解决的最本质问题,最终一致性不是消息队列的必备特性,确实可以依靠消息队列来做最终一致性的事情
参考
https://www.cnblogs.com/hapjin/p/10926882.html https://zhuanlan.zhihu.com/p/108564156 https://cloud.tencent.com/developer/article/1530498 https://www.jianshu.com/p/449074d97daf
at most once/at least once/exactly once
kafka推送消息采用的是pull模式,consumer 就可以根据自己的消费能力来消费数据 pull的缺点是什么? 如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询, 直到新消息到 t 达。为了避免这点,Kafka 有个参数可以让 consumer 阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发
kafka是如何高效存储消息的? https://cloud.tencent.com/developer/article/1421267 kafka的每个partition是一个有序的,不变的消息队列,消息总是被追加到尾部。一个partition不能被切分成多个散落在多个broker上或者多个磁盘上。 同时为了防止每个partition的数据过长,partition被划分成多个segment来组织数据。 当Kafka要写数据到一个partition时,它会写入到状态为active的segment中。如果该segment被写满,则一个新的segment将会被新建,然后变成新的“active” segment。 segment以该segment的base offset作为自己的名称。 在操作系统上,一个partition就是一个目录,每个segment由一个index文件和log文件组成 每个log文件是存储消息数据,在磁盘上的数据格式和producer发送到broker的数据格式一模一样,也和consumer收到的数据格式一模一样。由于磁盘格式与consumer以及producer的数据格式一模一样,这样就使得Kafka可以通过零拷贝(zero-copy)技术来提高传输效率。 每个index文件负责映射消息offset在log文件中的位置 索引文件是内存映射(memory mapped)的,offset查找使用二分查找来查找小于或等于目标offset的最近offset。
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。 Memory Mapped Files(后面简称mmap)也被翻译成内存映射文件,它的工作原理是直接利用操作系统的Page来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。 通过mmap,进程像读写硬盘一样读写内存,也不必关心内存的大小有虚拟内存为我们兜底。 mmap其实是Linux中的一个用来实现内存映射的函数,在Java NIO中可用MappedByteBuffer来实现内存映射。
什么是零拷贝?kafka用零拷贝实现了什么? https://cloud.tencent.com/developer/article/1421266 传统的文件拷贝并转发的流程通常需要从用户态转为核心态,经过read buffer,然后返回给用户态的应用层buffer,然后在切换为核心态,拷贝数据到核心态的socket buffer,然后发送到网卡 dma direct memory access,可以让某些硬件子系统去访问系统主内存,不需要再进行上下文切换、依赖cpu调度等操作,直接去访问内存。 很多硬件支持dma,包括网卡、显卡、声卡 传统的文件操作是通过java.io.DataOutputStream、java.io.FileInputStream来实现文件读取写入 零拷贝是通过java.nio.channels.FileChannel中transferTo方法来实现 transferTo方法底层是基于操作系统的sendfile这个system call来实现的(不再需要拷贝到用户态了) sendfile负责把数据从某个fd(file descriptor)传输到另一个fd
sendfile是零拷贝的一种实现方式,零拷贝有两种实现方式: https://cloud.tencent.com/developer/news/333695 rocketmq和kafka都使用了零拷贝,只不过两者使用的零拷贝的实现方式不同 rocket mq使用mmap+write,因为有小块数据传输的需求,效果会比 sendfile 更好 但是RocketMQ控制mmap映射的内存分配与释放的地方非常复杂,稍有不慎就会出问题。 KAFKA的索引文件使用mmap+write 方式,data文件使用sendfile 。
1、mmap 内存映射 当我们去读取文件的时候, 通常做法是这样的,发生了两次io拷贝,第一次是将磁盘中的文件内容拷贝到os文件缓冲区read buffer,第二次将os文件缓冲区read buffer的数据拷贝到用户缓冲区 使用mmap时,只会发生一次io拷贝,就是将磁盘文件内容拷贝到os文件缓冲区,之后进行一些其它复杂操作,例如将相应的os文件区映射到进程的地址空间 评价:尽管可以减少一次io拷贝,实现很复杂,调用将会带来额外的开销,因此在一些情况下,没有使用的必要 优点: 访问小文件时,直接使用或将更加高效。 缺点:不能很好的利用 DMA 方式,会比 sendfile 多消耗 CPU,内存安全性控制复杂,需要避免 JVM Crash问题。 2、sendfile mmap的流程不仅会有io拷贝的成本,还有线程上下文切换的开销,普通流程读取磁盘内容并发送需要发送4次io拷贝,4次上下文切换,linux为了减少上下文切换和io拷贝带来的开销, 使用sendfile时,实际发生3次io拷贝,第一次将磁盘中的文件内容拷贝到 OS 的文件系统缓冲区,第二次是将 OS 缓冲区的数据拷贝到 socket 的发送缓冲区,最后一次是将 socket 发送缓冲区的数据发送到网卡驱动。 可以看到,减少了一次 I/O 拷贝和两次 context switch。如果网卡支持dma,还可以再减少一次 I/O 拷贝 优点:可以利用 DMA 方式,消耗 CPU 较少,大块文件传输效率高,无内存安全性问题。 缺点:小块文件效率低于 mmap 方式,只能是 BIO 方式传输,不能使用 NIO。 sendfile:FileChannel.transferTo()只有源为FileChannel才支持transfer这种高效的复制方式,其他如SocketChannel都不支持transfer模式。 当然,目的Channel没有这种限制。所以一般可以做FileChannel->FileChannel和FileChannel->SocketChannel的transfer。
kafka的ack机制是什么? 0不等 1等一个 -1全都等
kafka实现延迟队列、死信队列、重试队列? https://blog.csdn.net/jy02268879/article/details/106014372
kafka中的几个概念名词? ISR:in-sync replicas 副本同步队列 AR: assigned replicas 所有副本 ISR由leader维护,follower从leader同步数据有一些延迟,任意一个超过阈值都会把follower剔除出ISR, 存入OSR(Outof-Sync Replicas)列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
kafka中的分区器、序列化器、拦截器是否了解? 执行顺序是什么? kafka的生产者的架构是什么? https://blog.csdn.net/ThreeAspects/article/details/108130254 拦截器->序列化器->分区器 整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和Sender线程(发送线程)。 在主线程中由KafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用之后缓存到消息累加器(RecordAccumulator,也称为消息收集器)中。 Sender线程负责从RecordAccumulator中获取消息并将其发送到Kafka中。 https://blog.csdn.net/LINBE_blazers/article/details/104072886
消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1? offset+1 kafka怎么实现有且仅有消费一次? 什么情况下消息会重复消息,消息漏消费? 重复消费:消费者消费后没有commit offset(程序崩溃/强行kill/消费耗时/自动提交偏移情况下unscrible) 消息漏消费:消费者没有处理完消息 提交offset(自动提交偏移 未处理情况下程序异常结束) https://cloud.tencent.com/developer/article/1444056 下游消费方实现幂等性 https://cloud.tencent.com/developer/article/1444056
KafkaConsumer和kafkaProducer是否是线程安全? 怎么实现多线程安全消费? https://www.cnblogs.com/huxi2b/p/6124937.html KafkaProducer是线程安全的,因此我们鼓励用户在多个线程中共享一个KafkaProducer实例,这样通常都要比每个线程维护一个KafkaProducer实例效率要高 KafkaConsumer不是线程安全的,实现多线程消费有两种办法: 1、每个线程维护一个KafkaConsumer 2、一个kafkaConsumer,后面跟个线程池处理 从 Kafka 0.10.1.0 版本开始,KafkaConsumer 就变为了双线程的设计,即用户主线程和心跳线程。 https://time.geekbang.org/column/article/108512 所谓用户主线程,就是你启动 Consumer 应用程序 main 方法的那个线程, 而新引入的心跳线程(Heartbeat Thread)只负责定期给对应的 Broker 机器发送心跳请求,以标识消费者应用的存活性(liveness) 引入这个心跳线程还有一个目的,那就是期望它能将心跳频率与主线程调用KafkaConsumer.poll 方法的频率分开,从而解耦真实的消息处理逻辑与消费者组成员存活性管理。
为什么kafka的partition只能增加不能减少? https://blog.csdn.net/u013256816/article/details/82804564 __consumer_offsets 以下划线开头,保存消费组的偏移
kafka中的事务是什么? Kafka在0.11版本中除了引入了Exactly Once语义,还引入了事务特性。 https://zhmin.github.io/2019/05/20/kafka-transaction/ https://juejin.cn/post/6867040340797292558 http://matt33.com/2018/10/24/kafka-idempotent/ kafka exactly once语义原理及适用场景是什么? https://www.infoq.cn/article/kafka-analysis-part-8 https://www.jianshu.com/p/64c93065473e
Kafka的那些设计让它有如此高的性能? https://cloud.tencent.com/developer/article/1488144 零拷贝,页缓存,顺序写 https://blog.nowcoder.net/n/33f1c7837f3f4d3f8d7e9688053f1f3d
kafka与zookeeper的关系是什么? ZooKeeper 主要为 Kafka 提供元数据的管理的功能。 https://github.com/Snailclimb/JavaGuide/blob/master/docs/system-design/distributed-system/message-queue/Kafka%E5%B8%B8%E8%A7%81%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93.md
kafka如何保证消息不丢失? 生产端:ListenableFuture<SendResult<String, Object»添加回调函数 + 重试 消费者:手动提交offset broker不丢:ack设置>1个 https://juejin.cn/post/6844904094021189639 https://www.jianshu.com/p/f47c36de8ee4
kafka什么情况下消息会丢失? ack=0 消息未同步给副本之前宕机 页缓存落磁盘之前宕机
kafka选主? https://juejin.cn/post/6844903846297206797 https://my.oschina.net/u/3070368/blog/4338739
kafka与时间轮? https://www.infoq.cn/article/erdajpj5epir65iczxzi
kafka 消息压缩? 压缩最好是针对批量消息进行压缩,吞吐量会好,如果只针对单条消息压缩,可能会适得其反 https://blog.csdn.net/u013256816/article/details/73197583 https://www.jianshu.com/p/d69e27749b00
kafka问题? 1、kafka性能很高的原理是什么? https://blog.nowcoder.net/n/33f1c7837f3f4d3f8d7e9688053f1f3d https://xie.infoq.cn/article/c06fea629926e2b6a8073e2f0 2、kafka的数据落到磁盘,是如何实现高效存储和检索的? https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 3、谈谈你了解的kafka选主机制? http://blog.mozhu.org/2017/11/30/kafka/kafka_leader_election.html https://juejin.cn/post/6844903846297206797 https://my.oschina.net/u/3070368/blog/4338739 4、kafka中有offset rewind的概念,你了解是什么吗?了解过kafka的unclean选举吗? http://gebilaowang.info/2017/04/27/kafka-rewinds-data-lost/ 5、kafka新旧版本都会依赖zk,你了解zk在kafka中的作用是什么吗? https://github.com/Snailclimb/JavaGuide/blob/master/docs/system-design/distributed-system/message-queue/Kafka%E5%B8%B8%E8%A7%81%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93.md 6、你们当前项目中使用的kafka版本是什么?了解过最近kafka版本的一些重大改变吗 https://blog.csdn.net/qq_21439395/article/details/80392853 7、在你的项目中,如何保证消息不丢失呢? https://juejin.cn/post/6844904094021189639 https://www.jianshu.com/p/f47c36de8ee4 8、针对kafka的消息重复消费,你是如何理解的? https://cloud.tencent.com/developer/article/1444056 9、kakfa内部有很多定时任务,这些定时任务你知道通过什么实现的吗? https://www.infoq.cn/article/erdajpj5epir65iczxzi https://my.oschina.net/yinjihuan/blog/4486625 10、kafka producer是线程安全的吗?kafka producer的架构是怎么设计的? kafka consumer呢? https://www.cnblogs.com/huxi2b/p/6124937.html https://time.geekbang.org/column/article/108512 11、kafka有事务这种概念吗?kafka的事务指的是什么呢? https://zhmin.github.io/2019/05/20/kafka-transaction/ https://juejin.cn/post/6867040340797292558 http://matt33.com/2018/10/24/kafka-idempotent/
Leave a comment